
HOW to Create a Machine Learning Model in Python for Sales Prediction
Step-by-Step Guide to Building a Sales Prediction Model Using Python and Scikit-Learn

Introduction to Sales Forecasting
Why predict sales?
Sales forecasting is an essential aspect of business planning and management, as it enables companies to anticipate future demand, allocate resources efficiently, and minimize costs. Accurate sales predictions can lead to increased revenue, better customer satisfaction, and informed decision-making. Machine learning (ML) techniques are increasingly being used to improve sales forecasting, as they can analyze vast amounts of data and identify patterns that traditional statistical methods may overlook.
Machine Learning Fundamentals
Machine learning is a subset of artificial intelligence that allows computers to learn and make decisions without explicit programming. There are three primary types of machine learning:

Supervised learning: the algorithm is trained on a labeled dataset, where input-output pairs are provided. The goal is to learn a mapping from inputs to outputs, which can then be used to make predictions on new, unseen data.
Unsupervised learning: involves training the algorithm on an unlabeled dataset, where only input data is provided. The goal is to discover hidden structures and relationships within the data.
Reinforcement learning: algorithms learn by interacting with an environment and receiving feedback in the form of rewards or penalties. The goal is to learn an optimal policy that maximizes the cumulative reward over time.
Python Libraries for Machine Learning
There are numerous Python libraries available for implementing machine learning models. Some popular libraries include:

Scikit-learn
Scikit-learn is an open-source library that provides simple and efficient tools for data mining and data analysis. It includes various machine learning algorithms, such as classification, regression, clustering, and dimensionality reduction.
TensorFlow
TensorFlow is an open-source machine learning library developed by Google. It is designed for deep learning and can be used for various tasks, such as image recognition, natural language processing, and reinforcement learning.
Keras
Keras is a high-level neural networks API, written in Python, and capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, or Theano. It focuses on being user-friendly, modular, and extensible.
Steps to Create a Sales Forecasting Model
Data Collection
Data collection is the first step in creating a machine learning model for sales forecasting. You will need historical sales data, which typically includes information such as product, price, quantity, date, and customer demographics.
import pandas as pd
# Load the sales data from a CSV file
sales_data = pd.read_csv('sales_data.csv')
# Print the first few rows of the data to verify it loaded correctly
print(sales_data.head())In this example, we’re using pandas to read a CSV file named sales_data.csv and store the data in a variable called sales_data. The head() function is then used to print the first few rows of the data to ensure it loaded correctly.
Once the data is loaded, it can be preprocessed and prepared for use in a machine learning model. This may involve cleaning the data, transforming it into a suitable format, and selecting relevant features.
Finally, the data can be split into training and testing sets, and a machine learning model can be trained on the training set to predict sales on the test set.
Data Preparation
Data preparation involves preprocessing the data to ensure that it is suitable for use in a machine learning model. Here’s an example of how to preprocess sales data using Python and the pandas library:
import pandas as pd
# Load the sales data from a CSV file
sales_data = pd.read_csv('sales_data.csv')
# Remove duplicates
sales_data.drop_duplicates(inplace=True)
# Fill missing values with the mean
sales_data.fillna(sales_data.mean(), inplace=True)
# Encode categorical variables using one-hot encoding
sales_data = pd.get_dummies(sales_data, columns=['product', 'customer_gender'])
# Normalize the numerical variables
numerical_cols = ['price', 'quantity']
sales_data[numerical_cols] = (sales_data[numerical_cols] - sales_data[numerical_cols].mean()) / sales_data[numerical_cols].std()
# Create new features based on existing ones
sales_data['revenue'] = sales_data['price'] * sales_data['quantity']
sales_data['month'] = pd.to_datetime(sales_data['date']).dt.month
# Print the preprocessed data to verify it was transformed correctly
print(sales_data.head())We start by removing duplicates and filling missing values with the mean. Next, we encode the categorical variables using one-hot encoding, which creates a binary variable for each possible value of the categorical variable. We then normalize the numerical variables using standardization, which scales the data to have a mean of 0 and a standard deviation of 1. Finally, we create new features based on existing ones, such as revenue and month, which can help improve the accuracy of the model.
After preprocessing the data, it can be split into training and testing sets, and a machine learning model can be trained on the training set to predict sales on the test set.
Model Selection
Once the sales data has been preprocessed, the next step in creating a machine learning model for sales forecasting is model selection. Selecting the right machine learning model for your sales forecasting task depends on the nature of your data and the specific requirements of your business. Here’s an example of how to select a machine learning model for sales prediction using Python and the scikit-learn library:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# Load the sales data from a CSV file and preprocess it
sales_data = pd.read_csv('sales_data.csv')
# Preprocessing code goes here
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(sales_data.drop('sales', axis=1), sales_data['sales'], test_size=0.2, random_state=42)
# Train and evaluate linear regression
lr = LinearRegression()
lr.fit(X_train, y_train)
lr_preds = lr.predict(X_test)
lr_mae = mean_absolute_error(y_test, lr_preds)
lr_mse = mean_squared_error(y_test, lr_preds)
lr_r2 = r2_score(y_test, lr_preds)
# Train and evaluate decision tree
dt = DecisionTreeRegressor()
dt.fit(X_train, y_train)
dt_preds = dt.predict(X_test)
dt_mae = mean_absolute_error(y_test, dt_preds)
dt_mse = mean_squared_error(y_test, dt_preds)
dt_r2 = r2_score(y_test, dt_preds)
# Train and evaluate neural network
nn = MLPRegressor(hidden_layer_sizes=(50, 50))
nn.fit(X_train, y_train)
nn_preds = nn.predict(X_test)
nn_mae = mean_absolute_error(y_test, nn_preds)
nn_mse = mean_squared_error(y_test, nn_preds)
nn_r2 = r2_score(y_test, nn_preds)
# Print the evaluation metrics for each model
print('Linear Regression - MAE:', lr_mae, 'MSE:', lr_mse, 'R-squared:', lr_r2)
print('Decision Tree - MAE:', dt_mae, 'MSE:', dt_mse, 'R-squared:', dt_r2)
print('Neural Network - MAE:', nn_mae, 'MSE:', nn_mse, 'R-squared:', nn_r2)In this example, we’re using scikit-learn to split the preprocessed sales data into training and testing sets, and then train and evaluate three different machine learning models: linear regression, decision tree, and neural network. We use mean absolute error (MAE), mean squared error (MSE), and R-squared as evaluation metrics to compare the performance of each model.
After selecting the best machine learning model for your sales forecasting task, the final step is to use it to make predictions on new, unseen data
Model Training
After selecting the best machine learning model for your sales forecasting task, the next step is model training. Model training involves feeding the input features (X) and the target variable (y) to the algorithm, which adjusts its internal parameters to minimize the error between its predictions and the actual values. Here’s an example of how to train a machine learning model for sales prediction using Python and the scikit-learn library:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Load the sales data from a CSV file and preprocess it
sales_data = pd.read_csv('sales_data.csv')
# Preprocessing code goes here*
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(sales_data.drop('sales', axis=1), sales_data['sales'], test_size=0.2, random_state=42)
# Train the linear regression model
lr = LinearRegression()
lr.fit(X_train, y_train)
# Print the coefficients and intercept of the linear regression model
print('Coefficients:', lr.coef_)
print('Intercept:', lr.intercept_)In this example, we’re using scikit-learn to split the preprocessed sales data into training and testing sets, and then train a linear regression model on the training set. The fit() method is used to train the model on the input features (X_train) and target variable (y_train).
After training the machine learning model, the next step is to evaluate its performance on the test set to ensure that it can generalize well to new, unseen data. This is done using evaluation metrics such as mean absolute error (MAE), mean squared error (MSE), and R-squared.
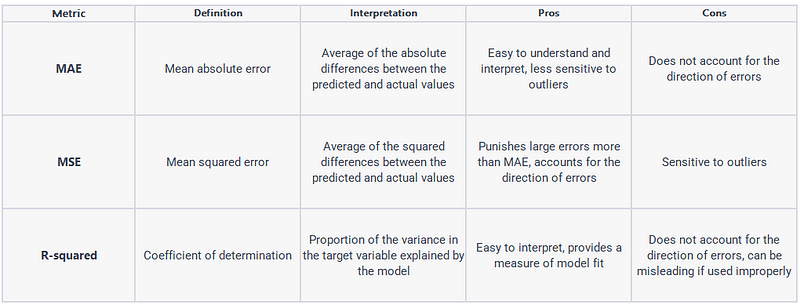
Model Evaluation
After training a machine learning model for sales forecasting, the next step is to evaluate its performance on unseen data to ensure that it generalizes well to new data points. This is typically done by splitting the dataset into a training set and a test set, and then comparing the model’s predictions to the actual values in the test set. Here’s an example of how to evaluate a machine learning model for sales prediction using Python and the scikit-learn library:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# Load the sales data from a CSV file and preprocess it
sales_data = pd.read_csv('sales_data.csv')
# Preprocessing code goes here
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(sales_data.drop('sales', axis=1), sales_data['sales'], test_size=0.2, random_state=42)
# Train the linear regression model
lr = LinearRegression()
lr.fit(X_train, y_train)
# Evaluate the performance of the model on the test set
lr_preds = lr.predict(X_test)
lr_mae = mean_absolute_error(y_test, lr_preds)
lr_mse = mean_squared_error(y_test, lr_preds)
lr_r2 = r2_score(y_test, lr_preds)
# Print the evaluation metrics for the model
print('Linear Regression - MAE:', lr_mae, 'MSE:', lr_mse, 'R-squared:', lr_r2)In this example, we’re using scikit-learn to split the preprocessed sales data into training and testing sets, and then train a linear regression model on the training set. We then use the predict() method to make predictions on the test set, and calculate the mean absolute error (MAE), mean squared error (MSE), and R-squared to evaluate the performance of the model on the test set.
It’s also important to check for overfitting, which occurs when the model performs well on the training data but poorly on the test data. One way to check for overfitting is to use cross-validation, which involves splitting the data into multiple training and testing sets and averaging the performance metrics across them. Another way is to use regularization techniques, which penalize complex models to prevent overfitting.
By evaluating the performance of the machine learning model on unseen data, you can ensure that it will generalize well to new data points and provide accurate sales forecasts for your business.
Conclusion
Creating an advanced machine learning model for sales prediction in Python involves several key steps, including data collection, data preparation, model selection, model training, and model evaluation. By carefully following these steps and utilizing the appropriate Python libraries, you can develop an accurate and efficient sales forecasting model that can help your business make informed decisions and achieve its goals.
FAQs
What is the difference between machine learning and traditional statistical forecasting methods?
Machine learning models can automatically learn from data and adapt to new information, while traditional statistical methods require manual parameter tuning and may not be able to capture complex relationships within the data.
How can I improve the accuracy of my sales forecasting model?
You can improve the accuracy of your model by using more high-quality data, feature engineering, selecting the most appropriate model, and fine-tuning the model’s hyperparameters.
How do I choose the best machine learning model for my sales forecasting task?
It’s often a good idea to try multiple models and compare their performance using evaluation metrics such as MAE, MSE, and R-squared. The best model for your task will depend on the nature of your data and your specific business requirements.
Can machine learning models predict sales for new products without historical data?
While historical data is usually essential for training machine learning models, techniques such as transfer learning and incorporating external data sources (e.g., market trends, product features, and competitor information) can help make predictions for new products with limited or no historical data.
How often should I update my sales forecasting model?
The frequency at which you update your model depends on factors such as the stability of your market, the rate of change in your data, and the computational resources available. It’s important to monitor your model’s performance regularly and update it as needed to maintain its accuracy and relevance.
🐼.